MACHINE LEARNING | CHARLES WANG

Santa Clara Adult Education Build Machine Learning Applications with Linux, Python, and Spark UCSC Extension The Internet of Things: Big Data Processing and Analytics |
| Spark |
Machine Learning Library: MLlibSpark is built on the concept of distributed datasets, which contain arbitrary Java or Python objects. You create a dataset from external data, then apply parallel operations to it. The building block of the Spark API is its RDD API. In the RDD API, there are two types of operations: transformations, which define a new dataset based on previous ones, and actions, which kick off a job to execute on a cluster. In Spark, a DataFrame is a distributed collection of data organized into named columns. Users can use DataFrame API to perform various relational operations on both external data sources and Spark’s built-in distributed collections without providing specific procedures for processing data. Also, programs based on DataFrame API will be automatically optimized by Spark’s built-in optimizer, Catalyst. A SparkContext represents the connection to a Spark cluster, and can be used to create RDD and broadcast variables on that cluster. Spark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively. It is available in either Scala (which runs on the Java VM and is thus a good way to use existing Java libraries) or Python Spark also supports pulling data sets into a cluster-wide in-memory cache. This is very useful when data is accessed repeatedly, such as when querying a small “hot” dataset or when running an iterative algorithm like PageRank. MLlib is Spark's machine learning (ML) library. Its goal is to make practical machine learning scalable and easy.
One way to create an instance of an algorithm is to create a Transformer. For example I can use a type of Transformer called a Model to read a DataFrame of features and output a DataFrame with a column of predictions.
https://spark.apache.org/docs/latest/quick-start.html https://spark.apache.org/docs/latest/cluster-overview.html https://spark.apache.org/docs/latest/rdd-programming-guide.html Spark vs. Hadoop MapReducehttps://www.xplenty.com/blog/apache-spark-vs-hadoop-mapreduce/ |
| Scala |
Scala is a general-purpose programming language. Scala has full support for functional programming and a strong static type system. Designed to be concise,[10] many of Scala's design decisions were inspired by criticism of Java's shortcomings. Example: linr11.scala vs. logr12.sclaThe script should download prices and predict daily direction of GSPC. It should generate a label which I assume to be dependent on price calculations. A label should classify an observation as down or up. Down is 0.0, up is 1.0. It should generate independent features from slopes of moving averages of prices. It should create a Linear/Logistic Regression model from many years of features. |
| AWS |
IoT: Big Data Processing and Analytics
Amazon EC2 is a cloud-based service that allows you to quickly configure and launch new servers in a pay-as-you-go model. Once it's running, an EC2 instance can be used just like a physical machine in your office. The only difference is that it lives somewhere on the Internet, or "in the cloud". We get a pre-built distribution of Apache Spark running on a Linux server, using two Amazon Web Services (AWS) offerings: Amazon Elastic Cloud Compute (EC2) and Identity and Access Management (IAM). We configure and launch an EC2 instance and then install Spark, using the Spark interactive shells to smoke test our installation. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html |
| Linear vs. Logistic Regression |
|
Regression is applied to determine the strength of a relationship between one dependent variable and other changing variables (known as independent variables). Logistic regression and linear regression are similar in nature but different in regards to the problems they solve. Linear regression addresses numerical problems and forms numerical predictions (in numbers). Whereas, logistic regression is used within classification algorithms to predict discrete classes and observce which class a new data point belongs to. Logistic regression is commonly used in binary classification to predict two discrete classes. To do this, it adds a Sigmoid function to compute the result and converts numerical results into a number of probability between 0 and 1. |
| Supervised vs. Unsupervised Learning Algorithms |
The only difference between supervised and unsupervised learning lies in the type of training data use use. In supervised learning you provided labelled training data. This means that each example you feed into your algorithm is classified into a recognizable data class or type. Unsupervised learning is defiend by unclassified traiing data. Essentially, you provide a machine with thousands of problems and their results, but you do not explain how the result is calculated. Supervised Learning:
Unsupervised Learning:
The Naive Bayes algorithm is a technique based on the Bayes' Theorem which is used for classification. The technique utilizes an assumption of independence among predictors. To put things simply, the Naive Bayes classifier assumes that the presence of a feature class is unrelated to the other featres in the class. The Naive Bayes algorithm performs well in cases where there are multiple classes, and when categorical input variables are involved. Using python library, you can build a Naive Bayes model. There are three types of Naive Bayes model under scikit learn library: Gaussian, Multinomial, and Bernoulli. As a classification algorithm, Logistic Regression is used to predict a binary outcome such as 1 or 0, Yes or No, True of False depending on a set of given independent variable. ROC curve: ROC stands for Receiver Operating Charcteristic. It summarizes the model performance by weighing up the trade-offs between the true positive rate (TPR) and the false positive rate (FPR). Support Vector Machine (SVM) plots each data item as a point in n-dimentional space. In this case, n is the number of features we have and the value of each feature will translate to the value of a particular coordinate. The task is then to perform classification by determine the hyperplane that differentiates the two classes best. Descending Dimension Algorithm:Principle Component Analysis (PCA), also known as general factor analysis, is an unsupervised approach to examine the interrelatons among a set of variables. PCA works by creating an orthogonal line perpendicular (at a right angle) to a regression line. The orthogonal line then takes the role of the new y-axis. Support Vector Machine:SVM resembles other regression algorithms, including logistic regression, but with stricter conditions. SVM is better at drawing classification boundary lines. SVM is less sensitive to anomalies and actually minimalizes their impact on overall classifications. SVM's real strength is in high-dimensional data with multiple features. |
| TensorFlow |
TensorFlow is an open source software library for machine learning in various kinds of perceptual and language understanding tasks. It is currently used for both research and production by 50 different teams in dozens of commercial Google products, such as speech recognition, Gmail, Google Photos, and search,many of which had previously used its predecessor DistBelief. TensorFlow was originally developed by the Google Brain team for Google's research and production purposes and later released under the Apache 2.0 open source license on November 9, 2015. TensorFlow™ is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API. C and C++ are the preferred languages to directly edit and perform mathematical operations on the GPU. However, Python can instead be used and converted into C when used in combination with Google's TensorFlow. Tensorflow is Google's answer to machine learning and runs on top of Python. As the most popular machine learning framework, TensorFlow supports various machine learning algorithm, neural networks, calculus, and reinforcement learning. Neural NetworkAn Artificial Neural Network (ANN) is an information processing paradigm that is inspired by the way biological nervous systems, such as the brain, process information. The key element of this paradigm is the novel structure of the information processing system. It is composed of a large number of highly interconnected processing elements (neurones) working in unison to solve specific problems. ANNs, like people, learn by example. An ANN is configured for a specific application, such as pattern recognition or data classification, through a learning process. Learning in biological systems involves adjustments to the synaptic connections that exist between the neurones. This is true of ANNs as well. Neural networks, with their remarkable ability to derive meaning from complicated or imprecise data, can be used to extract patterns and detect trends that are too complex to be noticed by either humans or other computer techniques. A trained neural network can be thought of as an "expert" in the category of information it has been given to analyse. This expert can then be used to provide projections given new situations of interest and answer "what if" questions. Other advantages include: 1. Adaptive learning: An ability to learn how to do tasks based on the data given for training or initial experience. 2. Self-Organisation: An ANN can create its own organisation or representation of the information it receives during learning time. 3. Real Time Operation: ANN computations may be carried out in parallel, and special hardware devices are being designed and manufactured which take advantage of this capability. 4. Fault Tolerance via Redundant Information Coding: Partial destruction of a network leads to the corresponding degradation of performance. However, some network capabilities may be retained even with major network damage. |
| Node.js |
Node.js is an open-source, cross-platform JavaScript runtime environment for developing a diverse variety of tools and applications. Although Node.js is not a JavaScript framework, many of its basic modules are written in JavaScript, and developers can write new modules in JavaScript. The runtime environment interprets JavaScript using Google's V8 JavaScript engine. Node.js has an event-driven architecture capable of asynchronous I/O. These design choices aim to optimize throughput and scalability in Web applications with many input/output operations, as well as for real-time Web application. Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient. Node.js' package ecosystem, npm, is the largest ecosystem of open source libraries in the world. Node.js allows the creation of Web servers and networking tools using JavaScript and a collection of "modules" that handle various core functionality. Modules are provided for file system I/O, networking (DNS, HTTP, TCP, TLS/SSL, or UDP), binary data (buffers), cryptography functions, data streams and other core functions. Node.js's modules use an API designed to reduce the complexity of writing server applications. Node.js is primarily used to build network programs such as Web servers, making it similar to PHP. The biggest difference between Node.js and PHP is that most functions in PHP block until completion (commands execute only after previous commands have completed), while functions in Node.js are designed to be non-blocking (commands execute in parallel, and use callbacks to signal completion or failure). |
| Keras |
Keras is a high-level neural networks library, written in Python and capable of running on top of either TensorFlow or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research. Keras is a powerful easy-to-use Python library for developing and evaluating deep learning models. |
| Seaborn |
Seaborn is a Python visualization library based on matplotlib that provides a high-level interface for drawing attractive statistical graphics. Seaborn is tightly integrated with the PyData stack, including support for numpy and pandas data structures and statistical routines from scipy and statsmodels. Seaborn is a library for making attractive and informative statistical graphics in Python. |
| NumPy, Scikit-learn, and Pandas |
NumpPy is free and open source, and is Python's answer to MATLAB, which allows you to manage matrixes and work with large datasets. Scikit-learn provides access to a a range of popular shallow machine learning algorithms, including linear regression, Bayes' theorem, and support vector machine. Pandas enable data to be represented on a virtual spreadsheet tht you can manipulate directly from your code. The naming comes from the term 'panel data', which refers to its ability to create a series of panels, similar to sheets in an Excel spreadsheet. NumPy, Scikit-learn and Pandas can also be used together. Users can thereby draw on these three libraries to: load their data via NumPy; clean up and perform calculations with Pandas; and run machine learning algorithms through Scikit-learn. |
| R |
|
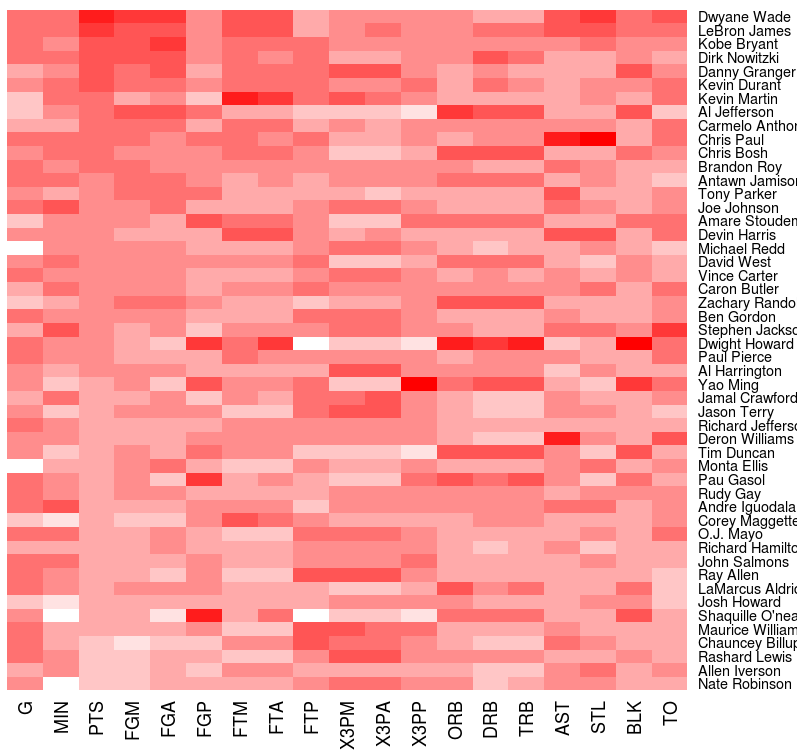
R is a programming language and software environment for statistical computing and graphics supported by the R Foundation for Statistical Computing. The R language is widely used among statisticians and data miners for developing statistical software and data analysis. Polls, surveys of data miners, and studies of scholarly literature databases show that R's popularity has increased substantially in recent years. Example: Use R to create a simple heatmap (source: NBA players 2008) Code: hw10.r |
| HDFS |
|
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS and YARN form the data management layer of Apache Hadoop. YARN is the architectural center of Hadoop, the resource management framework that enables the enterprise to process data in multiple ways simultaneously—for batch, interactive and real-time data workloads on one shared dataset. YARN provides the resource management and HDFS provides the scalable, fault-tolerant, cost-efficient storage for big data. https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html https://www.ibm.com/analytics/hadoop/hdfs https://hortonworks.com/apache/hdfs/ https://aws.amazon.com/getting-started/projects/analyze-big-data/ |
| Artificial Neural Networks - Deep Learning |
|
Similar to neurons in the human brain, neural networks are formed by interconnected neurons that interact with each other. Each connection has a numeric weight that can be altered and is based on experience. What makes deep learning 'deep' is the stacking of neurons that contain shallow algorithms. Neurons contain a range of shallow algorithms, including regression and clustering. Other shallow algorithms include decision trees and Bayes' theorem. Such algorithms are considered 'shallow' because they do not analyze information via multiple layers as neural networks can. A simple neural network can be divided into input, hidden, and output layers. Data is first received by the input layer, at which broad features are detected. The hidden layers then analyze and process that data, and based on previous computations, data becomes streamlned through the passing of each layer of neurons. The final result is shown as the output layer. |
| Decision Trees |
|
The downside of neural networks is that they require massive amounts of data and are demandinf on computational resources. Decision trees, on the other hand, bring with them a high level of efficiency, low cost, and are uniquely visual. These three benefits make this simple algorithm highly efficient at solving classification problems in machine learning. As a supervised technique, decision trees work by taking a sample dataset that includes classification results and returns a visual tree mapping the entire classification process. A decision tree will not only break down data and explain how a classification waa formulated, but it also produces a neat visual flowchart you can show to people. When creating a decision tree the aim at each step or branch of the tree is to minimize the level of data entropy. Entropy is a mathematical term that explains the measure of variance in the data amongst different classss. |